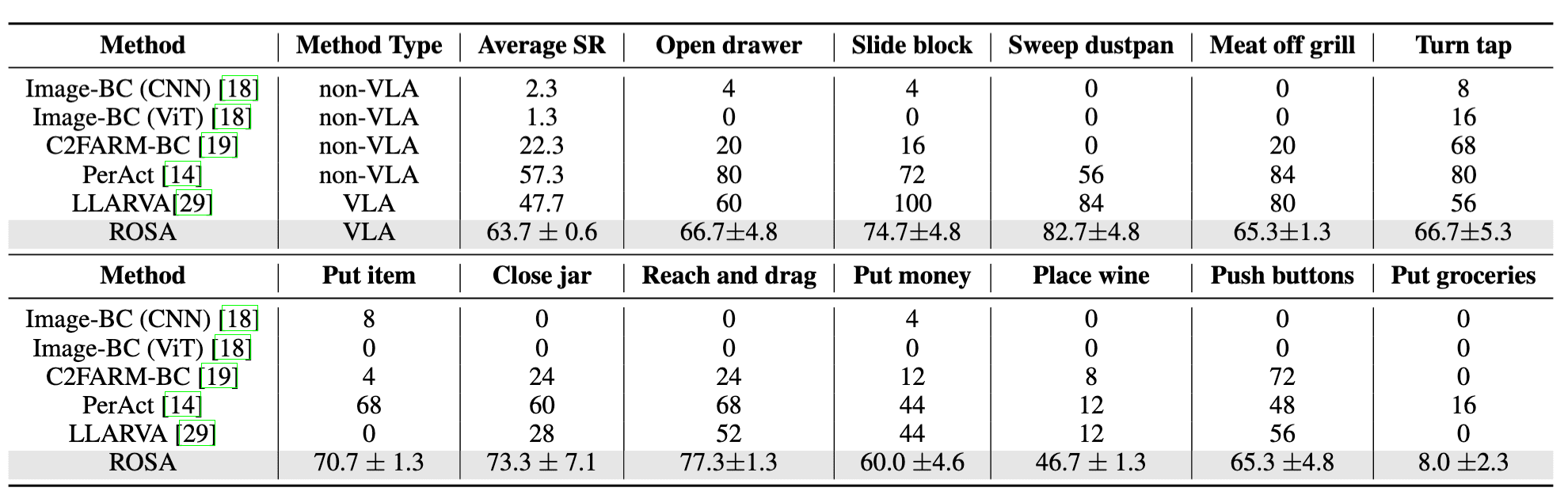
🎯 Motivation 🎯
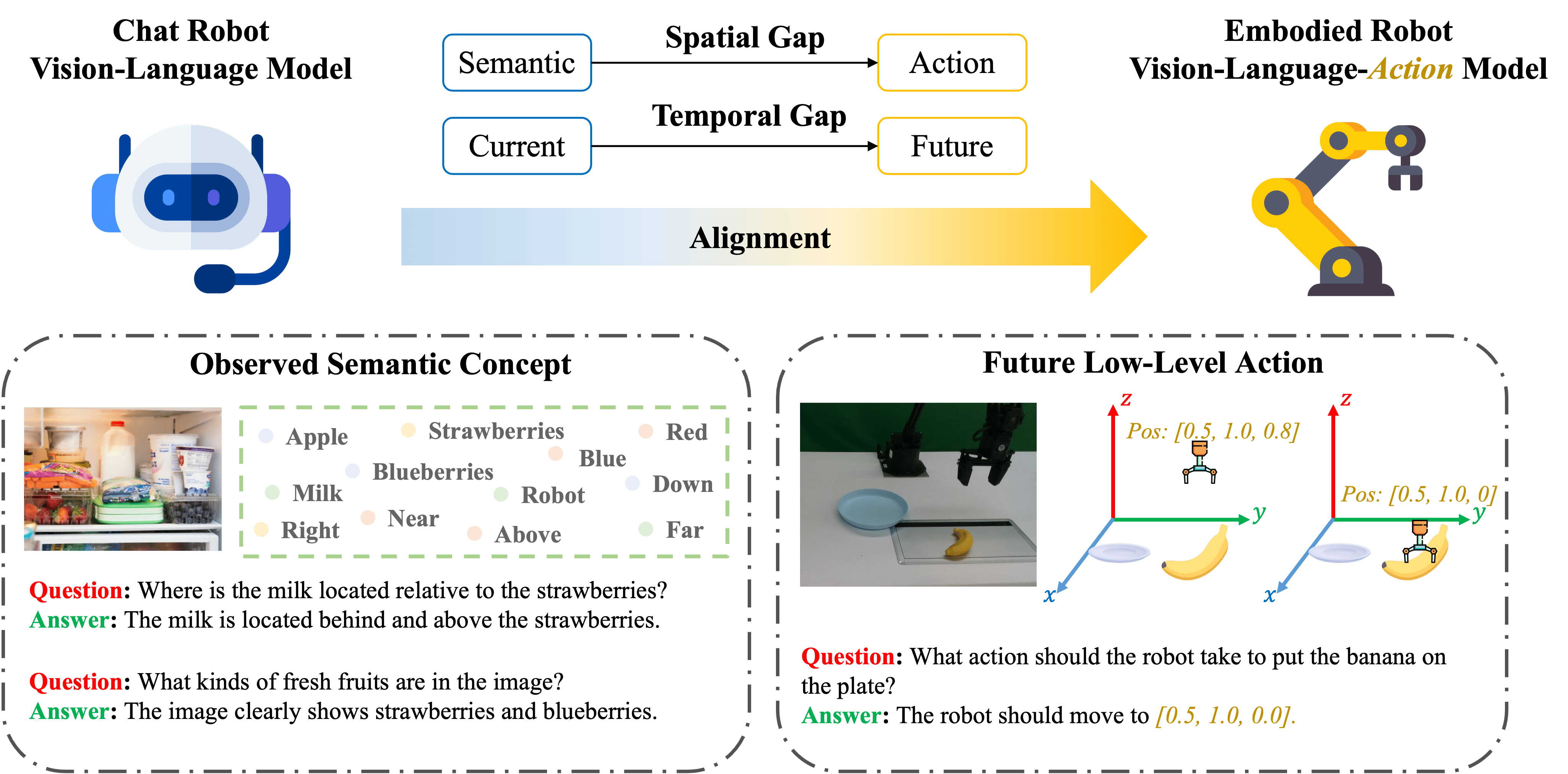
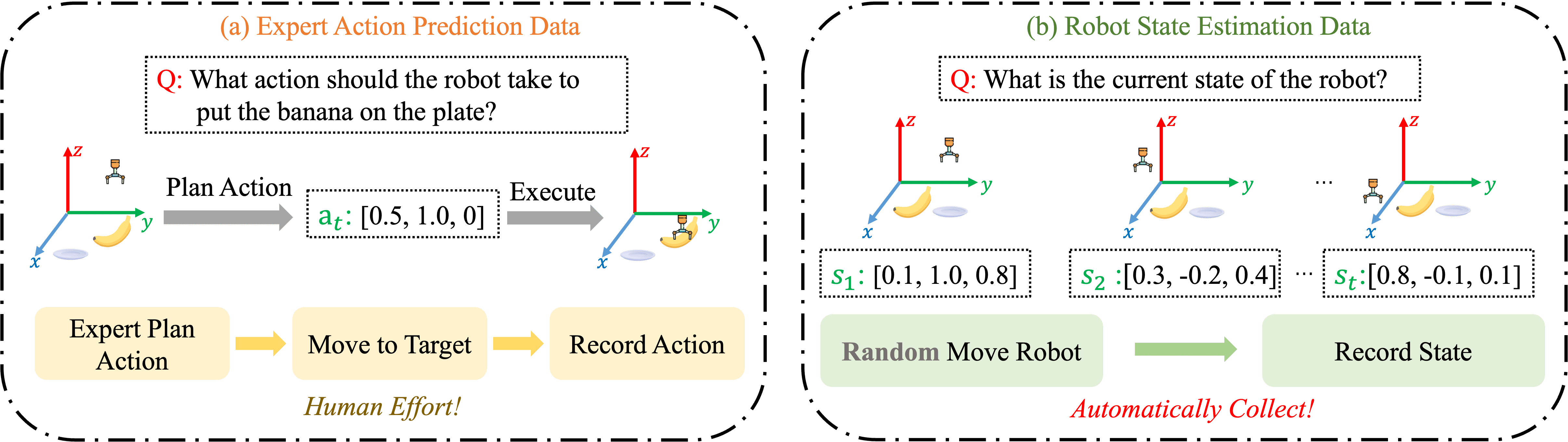
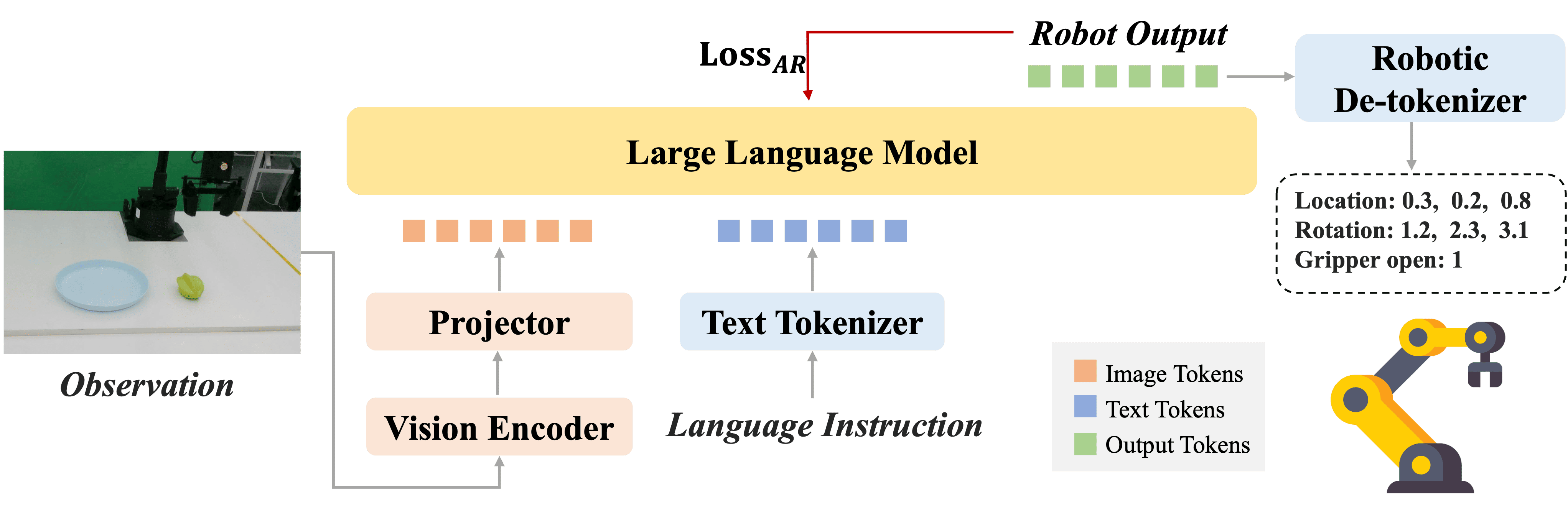
The spatial and temporal gaps in adapting VLMs to VLAs. VLMs are pretrained with large-scale VQA datasets to observe current high-level semantics in images, while VLAs are designed to predict low-level future actions in 3D space. The spatial-temporal gap poses challenges to the alignment process and results in data inefficiency in developing VLAs.